Región y sociedad, vol. 30, núm. 71, 2018
El Colegio de Sonora
José Luis Romo Lozano jlromo@aya.yale.edu
Universidad Autónoma Chapingo, Mexico
Francisco José Zamudio Sánchez zafra1949@gmail.com
Universidad Autónoma Chapingo, Mexico
Gladys Martínez Gómez gladysmartinezgomez@gmail.com
Universidad Autónoma Chapingo, Mexico
Luz Judith Rodríguez Esparza judithr19@gmail.com
Universidad Autónoma Chapingo, Mexico
Recepción: 10 Junio 2016
Aceptación: 07 Diciembre 2016
Resumen: El objetivo de este trabajo fue comparar dos índices subjetivos y tres objetivos, vía un análisis de dominancia, con los métodos de desviación estándar, CRITIC y entropía, para determinar el índice dominante. Las metodologías empleadas se basan en la teoría de índices y el análisis de dominancia en la teoría de redes. Uno de los índices subjetivos resultó ser el dominante, el cual utiliza los servicios básicos en la dimensión de recursos para una vida digna. Este resultado, como otros, está acotado por la imposibilidad de los índices (agregados de dos o más variables) de sujetarse a una relación de orden como el establecido en la recta numérica, por ello son empíricos y sólo señalan cierta regularidad. La aportación aquí es la diversidad de índices de desarrollo humano utilizada, que inducen a conjuntar técnicas estadístico-matemáticas para compararlos. Los servicios básicos se revelan como una opción razonable para una vida digna en el desarrollo humano.
Palabras clave: ponderación, índices, dominancia.
Abstract: The purpose of this study was to compare, via a dominance analysis, two subjective and three objective indexes by using the standard deviation, CRITIC and entropy methods in order to determine the dominant index. The methodologies used are based on the index theory and the dominance analysis in network theory. One of the subjective indexes turned out to be the dominant one, which uses basic services in resource dimension for a dignified life. This result, like others, is constrained by the inability of indexes (aggregates of two or more variables) to be subject to an order relation as the one established in the number line; for this reason they are empirical and only indicate certain regularity. The contribution here is the diversity of human development indexes used, which lead to combine statistical-mathematical techniques in order to compare them. Basic services prove to be a reasonable option for a dignified life in human development.
Key words : weighting, indices, dominance.
Introducción
La función de todo indicador es expresar, de manera condensada, información útil sobre el estado de cosas de una realidad compleja. En el contexto del análisis de políticas, los indicadores son útiles para identificar las tendencias y dirigir la atención hacia algunos aspectos; pueden ayudar en el establecimiento de prioridades y referencias para el monitoreo de desempeño en factores de interés (Organization for Economic Cooperation and Development, OECD 2008, 13). Los indicadores sociales satisfacen la necesidad de planear y reportar rasgos sociales complejos y cambiantes (Frones 2007, 6; Hurdrliková 2013, 459).
La ponderación constituye una fase importante en la propuesta de un indicador, es decir, la asignación de pesos a las variables (subindicadores o dimensiones), que son vitales porque su influencia es determinante en la cuantificación del desempeño social de los logros estimados (Munda y Nardo 2003, 2). Existen enfoques y métodos distintos para definir el peso de las variables que componen un indicador. Decancq y Lugo (2013) distinguen tres importantes: el derivado de datos, el normativo y el híbrido. El primer enfoque está en función de la distribución de los logros en la sociedad y no se basa, al menos explícitamente, en algún juicio de valor sobre las dimensiones; el segundo sólo depende de los juicios de valor y el tercero lo hace tanto de los datos y, de alguna forma, de la valoración de esos logros.
Este estudio se enmarca, pero no se inscribe en el debate conocido como la “guillotina de Hume”, el cual señala que muchas de las quejas sobre “lo que debiera ser” (afirmación normativa), están basadas en “lo que es” (afirmación descriptiva), situación considerada errónea puesto que ambas difieren, y no se puede derivar un “debiera” de un “ser” (Decancq y Lugo 2013, 3). Lo que aquí se busca es señalar las distancias entre los logros estimados, si se asume el “debe ser”, expresado por la ponderación (subjetiva), cuyo peso es igual al de las tres dimensiones del índice de desarrollo humano (IDH), establecida por el Programa de las Naciones Unidas para el Desarrollo (UNDP, por sus siglas en inglés) de 1991 o 2010, y los logros estimados en “lo que realmente es”, con pesos calculados a partir de métodos objetivos. En todo caso, lo que se puede interpretar de tales diferencias es la separación en la operación social de los esfuerzos aplicados en la consecución de los logros de desarrollo humano, en relación con los pesos establecidos por las opiniones expertas del UNDP.
El propósito de este artículo es comparar dos índices normativos, el IDH y el de desarrollo humano con servicios (IDHS), con tres índices objetivos: a) el IDHS, construido con los métodos de ponderación denominados desviación estándar (DE); b) el de importancia de criterios mediante la correlación entre criterios (CRITIC, por sus siglas en inglés) (C), y c) el de entropía (E). Tal comparación se hace a través de un método de dominancia, para determinar cuál de los cinco se podría considerar más robusto. Y, una vez seleccionado, se busca determinar las posibles razones que hacen que sea el más sólido, y se trata de obtener una medida de la confianza que se le puede tener y la forma en que se deben interpretar sus resultados.
La ponderación en el IDH
Esta investigación se orientó a la ponderación expresada en la asignación de pesos iguales (1/3) a la salud, la educación y al ingreso, las dimensiones (indicadores) que componen el IDH. Dicha ponderación se ubica en el marco del conjunto de críticas dirigidas a la construcción y la estimación del IDH, calculado a escala global desde 1990, y a partir de 1992 se inició la publicación de los primeros reportes nacionales, con la participación de Bangladesh, Camerún y Filipinas (De la Torre y Moreno 2010, 1).
En México, el primer informe fue realizado por profesores de la Universidad Autónoma Chapingo, quienes lo calcularon con los datos censales de 1995, y en el año 2000 se publicó en www.chapingo.mx/dicifo/demyc/IDH/bases/memo/memoria.html. Desde ese año en este sitio también se reportó el cálculo del IDHS, entre otros indicadores. La oficina del UNDP en México publicó por primera vez, en 2003, la estimación del IDH con los datos censales del año 2000 (De la Torre y Moreno 2010, 1).
Desde los primeros reportes globales, la estimación del IDH ha sido objeto de críticas sobre la metodología de cálculo y la conceptualización, razón por la cual se han propuesto muchas innovaciones, las cuales Gaye y Jha (2010) sugieren agrupar en cinco categorías: a) creación de medidas del desarrollo humano; b) uso de nuevas fuentes de datos; c) creación de medidas desagregadas del desarrollo humano; d) empleo de metodología novedosa y e) adaptación de la medida actual del desarrollo mediante la agregación/modificación de una dimensión nueva o de otra que ya existe.
En la discusión sobre el esquema de ponderación se distinguen la importancia y la compensación, temas de análisis íntimamente relacionados; sobre el primero, los teóricos del UNDP han argumentado que el uso de pesos iguales se justifica porque las tres dimensiones consideradas en el índice tienen la misma importancia (1991, 88). Sobre esto, Munda y Nardo señalan que cuando la función de agregación de un índice es una suma ponderada, como es el caso del IDH, hasta antes del reporte de 2010, el coeficiente multiplicativo de cada dimensión es igual a la tasa de sustitución, “lo que significa que la regla de agregación lineal implica pesos cuyos significados son necesariamente compensatorios y nunca de importancia simétrica” (2003, 40).
La tasa marginal de sustitución o tasa de compensación Rx,y entre la dimensión x y la y, está dada por
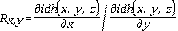

donde M x y m x denotan el valor máximo y mínimo de la dimensión x, del mismo modo que para M y y m y . Es decir, la tasa de intercambio entre dos indicadores es independiente, lo que permite evaluar la contribución marginal de cada uno por separado.
El cálculo de las tasas marginales de sustitución entre cualquier par formado por los tres indicadores contenidos en el IDH permite obtener sus precios implícitos, lo cual es una tradición para estimar equivalentes monetarios en la literatura económica. Sin embargo, el razonamiento basado en los precios contradice la idea de que el desarrollo humano no debiera ser parte de las estrategias para alcanzar un IDH más alto. “El IDH no es una función de producción o utilidad a ser maximizada, es más bien un índice de capacidades y las tasas de intercambio deben ser interpretadas de manera diferente” (Kovacevic 2010, 40). Foster y Sen (1997) pusieron el acento en esta discusión al argumentar que aun cuando se pueden obtener los precios implícitos en el IDH, son inapropiados para hacer comparaciones de bienestar, porque los índices de bienestar, como el IDH, no están basados en precios.
Aun con la explicación de Foster y Sen, en el informe de desarrollo humano de 2010 se cambió la forma de agregar los indicadores de una media aritmética, o suma ponderada, a la forma de media geométrica, lo cual redujo el grado de sustitución entre las dimensiones (UNDP 2010, 225), y quedó como sigue:

donde
InEsp : índice de esperanza de vida InEdu : índice de educación InIng : índíce del ingreso.Si bien la media geométrica reduce el grado de sustitución, el costo de hacerlo es obnubilar, en muchas situaciones, dos de las tres dimensiones porque, en general, el valor mínimo de las tres domina la media geométrica. Por ejemplo, si el valor del índice de salud es de 0.1, y el de educación e ingreso es de 0.9, su media geométrica es de 0.4327, la cual se ve dominada por el valor mínimo de las tres dimensiones. Debido a todo lo anterior, y por la importancia de las dimensiones del desarrollo humano, vía la ponderación que se hace de cada una, en este trabajo se construyen tres índices adicionales cuyo propósito es estimar esta importancia con los métodos objetivos ya mencionados.
Metodología
En el IDH, la dimensión de acceso a los recursos por lo general es aproximada, se estima por el producto interno bruto (PIB), sin embargo, en algunos países menos desarrollados la información sobre el PIB no se encuentra disponible con facilidad para unidades de escala menor, como por ejemplo la municipal. Una solución útil, propuesta por Ramírez (1999), es sustituirla por el acceso a los servicios de agua, luz y drenaje, para estimar el IDHS, calculado igual que el IDH considerando la variante anterior y manteniendo el método de suma ponderada.
Para cumplir con el objetivo señalado se estimó el peso de las tres dimensiones (salud, educación y servicios) mediante la aplicación de la desviación estándar, el método CRITIC y la entropía; se utilizaron los datos de 2010 de las tres dimensiones en los 2 454 municipios de México. Para cada conjunto de pesos obtenido se recalcularon los valores denotados por el IDHS/DE, el IDHS/C y el IDHS/E, en todas las entidades federativas, con el método de agregación suma ponderada. Al IDHS (igual peso con agregación aritmética), a los tres derivados de los métodos objetivos y al IDH del UNDP (igual peso con agregación geométrica, que utiliza al ingreso en lugar de los servicios) se les aplicó un análisis de robustez, a partir de relaciones de dominancia. Éste proporciona un ordenamiento estable, basado en la dominancia de un estado sobre los demás, para lo que se usan todos los índices que participan; a este ordenamiento aquí se le denomina orden por dominancia, y se comparó con el orden inducido por los cinco índices estudiados y, de éstos, al que se asemejó más al orden por dominancia se le declaró como el más robusto.
1. Método de suma ponderada (MSP) o agregación lineal
Este método de agregación es por mucho el más difundido y utilizado en el ámbito de los indicadores (OECD 2008, 104). Consiste en calificar una serie de alternativas en función de un grupo de criterios con un peso asignado (Podvezko 2011, 134). La calificación de la alternativa i, denotada por , i = 1, 2,…, m, se obtiene mediante la fórmula

donde
w j : peso del criterio (variable) j, j = 1, 2,…, n, obtenido por alguno de los métodos de ponderación x ij : valor del criterio j para cada alternativa i.En lo que sigue, las alternativas serán los 2 454 municipios de México y las variables los índices de esperanza de vida, educación y servicios. El IDHS es un ejemplo del uso de este método, el cual se calcula mediante la fórmula:

donde InSer es el índice de servicios, calculado como la media aritmética de los indicadores de agua, drenaje y energía eléctrica.
Métodos de ponderación
Desviación estándar
El método de determina el peso de los criterios en términos de sus desviaciones estándar mediante estas ecuaciones (Zardary et al. 2015, 35):
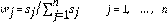

donde
w j : peso del criterio j, j = 1,…, n s j : desviación estándar del criterio j, j = 1,…, n m : número de alternativas x - j : media de los valores de las m alternativas del criterio j, j = 1,…, n.El método DE le da mayor peso al criterio más sensible. En contraste con el c, que se verá a continuación, no usa la información relacionada con las asociaciones lineales existentes entre los criterios. En este sentido, es más sencillo y útil cuando los criterios no están correlacionados.
Método CRITIC
Este método, propuesto por Diakoulaki et al. (1995), utiliza el análisis de correlación para detectar contrastes entre los criterios. Primero se valora cada vector columna v j de la matriz normalizada por suma, donde v j denota los registros del criterio j de todas las m alternativas, y la matriz normalizada está dada por [ v 1| v 2|…| v n ] cuyo orden es m x n.
Cada vector v j es caracterizado por su desviación estándar (s j ), la cual cuantifica la intensidad de los contrastes dentro del criterio correspondiente. De este modo, la desviación estándar de v j es una medida de la sensibilidad de ese criterio, para que se considere en el proceso de toma de decisiones. Además, se construye una matriz simétrica, de dimensiones n x n y el elemento genérico r jk , el cual es el coeficiente de correlación lineal entre los vectores v j y v k . Mientras los registros de las alternativas en los criterios j y k estén menos asociados linealmente, más bajo es el valor de r j k . En este sentido, la ecuación siguiente:

representa una medida de disociación del criterio j con respecto a la situación definida por el resto de ellos (Zardary et al. 2015, 33), lo cual significa que la información del criterio j no está contenida en el resto de los criterios involucrados, a medida que el valor de (8) sea mayor. El método C le asigna más peso a un criterio conforme se incrementa su varianza, y aporta más información, distinta a la de los otros criterios (menor coeficiente de correlación entre columnas) (Aznar y Guigarro 2012, 56).
La cantidad de información Cj, expresada por el j-ésimo criterio, se puede determinar conjuntando las medidas que cuantifican las dos nociones anteriores, mediante la interacción multiplicativa de la fórmula (9). Mientras más alto sea el valor Cj, más grande y sensible será la cantidad de información trasmitida por el criterio j. Los pesos objetivos se derivan normalizando estos valores a la unidad
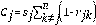

donde
Cj : cantidad de información del criterio j, j = 1, 2,…, n w j : peso del criterio j, j = 1, 2,…, n.El método C le asigna ponderaciones a los criterios utilizados en la medida del desarrollo humano (o en la que se esté construyendo), de acuerdo con la sensibilidad intrínseca en cada uno y a las asociaciones que existan entre ellos. El peso de un criterio será mayor a medida que sus valores se dispersen más alrededor de su valor promedio (una mayor desviación estándar) señalando condiciones heterogéneas entre las alternativas y, consecuentemente, la necesidad de incluir tal criterio en la medición del desarrollo humano. También, el método C le asignará mayor peso al criterio a medida que no esté relacionado con los demás, porque de ello se desprende que la información que aporta no está contenida en los otros que se estén usando. Este método pondera cada criterio haciendo uso simultáneo de dos de sus propiedades, ambas importantes en la medición del desarrollo humano.
Entropía
Zeleny y Cochrane (1982) propusieron el método de la entropía, que se identifica como una medida de la incertidumbre en la información, y se formula utilizando la teoría de las probabilidades. Aquí se estima la atracción (probabilidad) que tiene un atributo para tomar un valor. Al usar la notación definida, y recordar que las mediciones de los atributos son indicadores entre 0 y 1, se hace una partición en el intervalo [0,1] de s subintervalos del mismo ancho (se tomó s = 40 por determinar un ancho de intervalo de atracción suficientemente pequeño), sobre las cuales se estimará la atracción que se tiene de que el valor de una alternativa pertenezca a ese subintervalo. Si I k es el k-ésimo subintervalo, k = 1, 2, …, s, entonces I 1 = [0,1/s] y I k = [(k-1)/s,k/s] para k = 2, 3, …, s. Sea m kj el número de alternativas del atributo j = 1, 2, …, n, que tienen valores ( x i j ) en el subintervalo k = 1, 2, …, s. La probabilidad estimada p ^ k j de que un valor del atributo j esté en el subintervalo k está dada por:
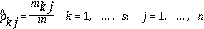
donde
m : número de alternativas que se están evaluando; de las cuales se obtiene la entropía del criterio j y su peso correspondiente, como sigue:


donde
E j : entropía del criterio j w j : ponderación del criterio j por el método de la entropía ln : función logaritmo natural.En el método E los valores de las alternativas x i j , en este caso en [0,1], para el criterio j, que se analiza, se trasforman a probabilidades p ^ k j , las cuales representan las oportunidades de ocurrencia de tales alternativas en el subintervalo I k y así, a mayor probabilidad más posibilidad de que un valor x i j ocurra en el subintervalo I k . La medida de entropía E j es más baja a medida que las probabilidades se concentran en algunos subintervalos (indica que los valores x i j se aglutinan en unos cuantos de ellos, es decir, que los valores de las alternativas son muy semejantes), y más alta cuando los valores de las alternativas están dispersos de manera uniforme entre todos los subintervalos. Un criterio tendrá mayor peso a medida que sus valores tiendan a concentrarse en un subintervalo, y que no se tenga presencia en el resto. Por tanto, en la medida del desarrollo humano, tendrán mayor peso los criterios en los que los valores de las alternativas estén concentrados en un subintervalo, esto señala que hay equidad en la distribución de ese criterio entre las alternativas evaluadas.
Relaciones de dominancia
Algunos investigadores han utilizado el criterio de dominancia para calificar la robustez de resultados; Cherchyle et al. (2008) analizaron las estimaciones del IDH en el marco de diferentes métodos de normalización de los datos de las dimensiones consideradas en el índice. Por otra parte, Sharpe y Brendor (2012) compararon la robustez de las clasificaciones generadas por varios métodos de ponderación en el índice de bienestar económico.
En las relaciones de dominancia, por lo general se manejan dos tipos: una dominancia fuerte y otra débil, y se definen en relación con un conjunto II de índices I. En esta caso, I contendrá a los cinco índices I que se estudian. Así, se dice que la alternativa x = x 1 , x 2 , … , x n domina fuertemente a la y = ( y 1 , y 2 , … , y n ) , denotada por x ≻ F y , si y sólo si
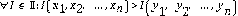
y, x domina débilmente a y , denotada por x > y , si y sólo si

donde I x 1 , x 2 , … , x n es una agregación particular ( I ϵ II ) y la alternativa está representada por x 1 , x 2 , … , x n , que aquí son los indicadores de educación, salud y servicios (ingreso en el IDH) de una entidad, es decir n = 3.
Si se comparan las entidades e 1 y e 2, la e 1 domina fuertemente a la e 2, si el orden de la e 1 es superior al de la e 2 en los cinco índices estudiados. Si, según un índice, la entidad e 1 tiene un orden superior al de la e 2 y, de acuerdo con otro, la e 2 tiene un orden superior al de la e 1, entonces ninguna de las dos domina fuertemente. En las comparaciones realizadas aquí, no se presentan dominancias débiles.
En el trabajo, las comparaciones de las 32 entidades del país se expresan en una matriz de orden 32x32; las hileras y columnas representan a cada una. Cuando una entidad en una hilera domine fuertemente a otra en una columna, en la celda correspondiente se escribirá 1, y 0 si es de otro modo. En la diagonal principal se escribirá 0 porque una entidad no se domina a sí misma. Esta matriz inicial se denota como A, y cuando se multiplique por sí misma y se obtenga A 2, ésta contendrá en la celda i, j (hilera i, columna j), el número de veces que el estado en la hilera i domina fuertemente al de la columna j, en dos pasos, lo cual significa que el estado en la hilera i domina fuertemente a otro, y éste lo hace de igual forma al de la columna j. A su vez, A 3 indicará el número de veces que el estado en la hilera i domina al de la columna j, en tres pasos, y así sucesivamente (Searle 1982, 46). La matriz A k tenderá a la matriz O cuando k tienda a infinito, ya que no existirá forma de que un estado domine fuertemente a otro en k pasos, cuando k sea demasiado grande. De modo que las dominancias posibles se tendrán en A 1, A 2, A 3, …, A k para una k, tal que A k+1 = O, es decir, la matriz nula. Con todas estas matrices se construirá una integradora A F de todas ellas, del modo siguiente: en la celda i, j de A F se colocará un 1 si existe al menos una A t , con t = 1, 2, …, k, en cuya celda i, j haya un valor diferente de 0 (es decir, estrictamente positivo), de otro modo en la celda i, j se colocará un 0.
Lo anterior conduce a que, una vez encontradas las formas en que un estado hilera domina a uno columna, basta que haya una forma de dominación del primero sobre el segundo, manifiesta en alguna A t , indistintamente de los pasos que se requieran para ello (es decir, sin importar el valor de t), para que se declare que el estado hilera domina al columna. La suma de la hilera i en A F proporcionará el número de estados dominados por el de esa hilera, lo que se denotará con H i . También, con la suma de la columna j en A F se conocerá el número de estados que dominan al de esa columna, lo que se indicará con G j . Para determinar el orden estabilizado y determinado por A F se calcularon los valores H i -G i , con i = 1, 2, …, 32 y se ordenaron de mayor a menor, los empates se resolvieron de acuerdo con los valores de H i (a mayor H i mejor lugar en el ordenamiento), si prevalecía alguno se resolvió con el número de veces que el estado dominaba en 1, 2, …, k pasos a los demás y, por último, si aún quedaban empates se ordenaron por medio de la mejor posición en los ordenamientos originales.
Resultados
Al observar los resultados de los métodos objetivos DE, C y E, se debe notar que éstos asignan pesos atendiendo a las características de los criterios; los dos primeros le dan más peso a los criterios distribuidos de forma más inequitativa entre los municipios del país, mientras que el tercero lo hace en sentido inverso. Sobre la aplicación de dichos métodos en el cálculo del peso de las dimensiones del desarrollo humano (véase Figura 1) se destaca lo siguiente:
Pesos asignados a las dimensiones por índice

-
El peso asignado a la educación es menor, pero similar al valor otorgado por el método subjetivo (33.33 por ciento).
-
El índice de servicios tiene un peso superior al que le asigna el método subjetivo: 50.05 por ciento en el C y 52.72 en el DE. La interpretación de esta sobreponderación por el método C obedece a que el vector correspondiente presenta una dispersión alta de los valores observados en los 2 454 municipios de México, así como un coeficiente de correlación bajo con respecto a los valores de los vectores de los índices de educación y esperanza de vida, lo que significa que aporta más información. La sobreponderación del método DE se explica también por el alto valor encontrado en la desviación estándar, la cual aquí no se corrige por las correlaciones lineales con los otros criterios. En el método E, al índice de servicios se le asigna un peso de 22.6 por ciento, bastante menor que el de los otros dos índices, lo que significa que sus valores están más dispersos en el intervalo [0,1] que los de salud y educación (lo cual está confirmado por el peso que DE le da al índice de desarrollo humano de servicios, es decir, hay más inequidad en la distribución de los servicios que en educación y salud entre los municipios del país.
-
Los métodos C y DE le asignan un peso sustancialmente menor a la salud, en comparación con la del método subjetivo, en cambio el e le otorga uno de 45.58 por ciento. Es decir, en términos de variabilidad y correlación, la importancia de la salud queda muy por debajo, mientras que la entropía la coloca en un lugar superior, esto señala que los valores del índice de desarrollo humano de salud están más concentrados en ciertos subintervalos que los de la educación y los servicios, hay más equidad en la dimensión de la salud.
Agregación mediante el MSP en las entidades del país
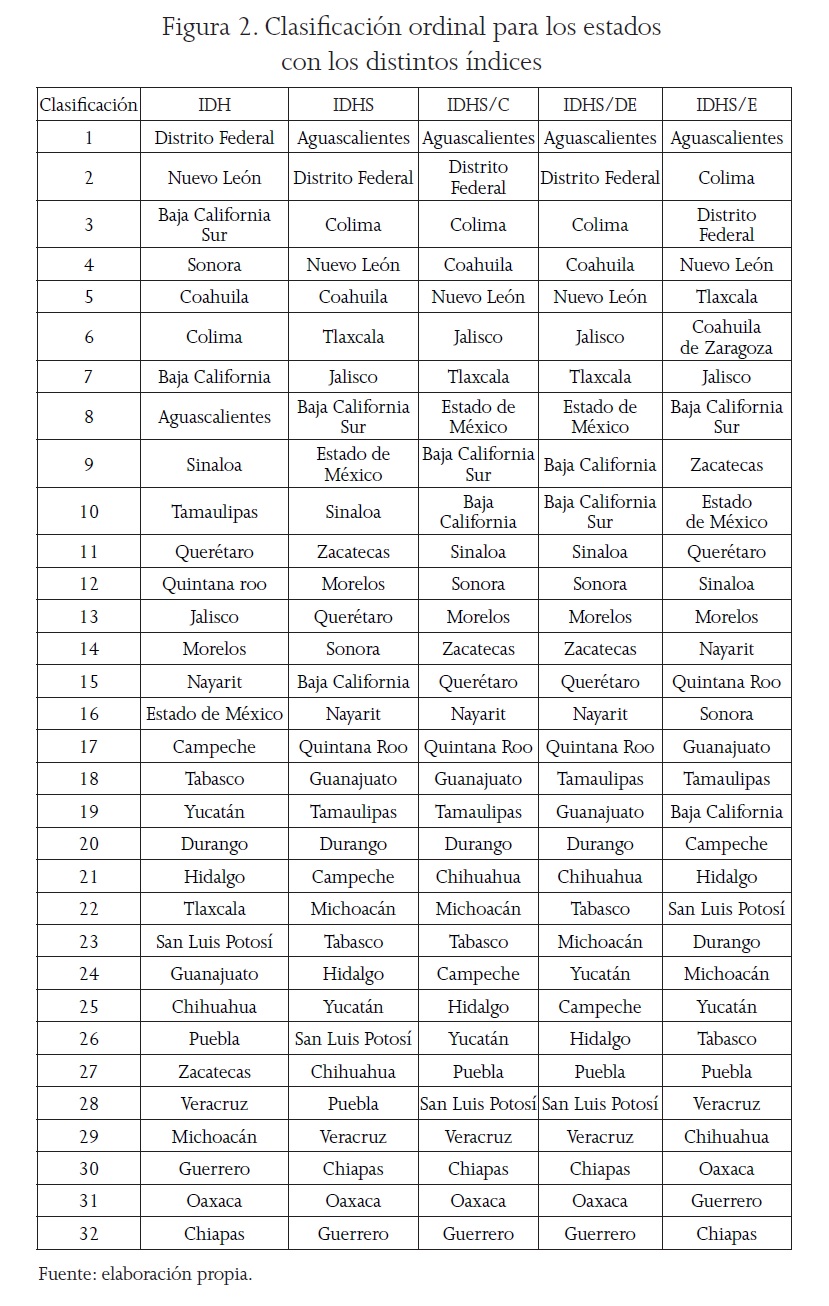
Después de que se calcularon los valores del índice de desarrollo humano para cada estado, con el mismo método de agregación propuesto por el UNDP (suma ponderada), y se aplicaron las ponderaciones determinadas por cada método (véase Figura 2), se obtuvieron distintos órdenes inducidos por cada uno de los cinco métodos. Todas las entidades presentaron modificaciones en el ordenamiento con respecto al obtenido por el IDHS con peso igual. Baja California tuvo mayor disparidad, pues subió cinco posiciones con la ponderación del método C; seis con la del DE, y bajó cuatro con la del E.
Clasificación ordinal para los estados con los distintos índices
Dominancia
Para analizar la robustez de los cinco métodos de ponderación se aplicó el de dominancia. La primera iteración registró las dominancias fuertes, identificadas en la matriz A de la Figura 3. Primero destaca que k tomó el valor de 10, es decir, se requirieron 11 iteraciones de la matriz original de dominancias para arribar a la matriz O, y saber todas las formas en que un estado hilera dominaba a uno columna.
Dominancia fuerte entre los estados, primera iteración

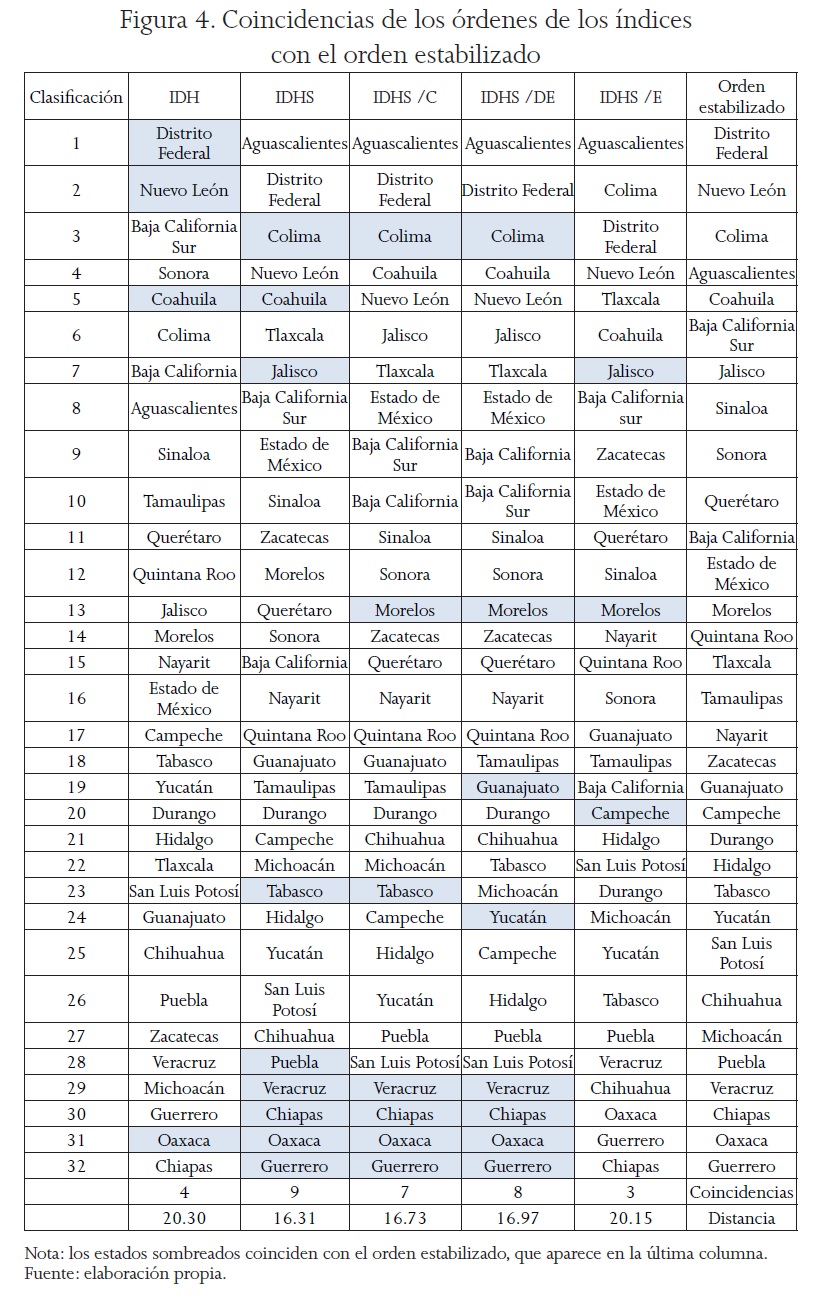
De la matriz final A F se obtuvo el orden estabilizado, que básicamente coloca en mejor posición al estado que domina a los que están por debajo de él, de acuerdo con los órdenes originales usados para contrastarse. El orden que tuvo mayor coincidencia con el generado por la matriz A F fue el del IDHS, con nueve entidades; le siguió el IDHS/DE, con ocho; en el IDHS/C coincidieron siete; el IDH, cuatro y el IDHS/E tuvo tres (véase Figura 4). En consecuencia, el IDHS se consideró el más robusto, puesto que induce un ordenamiento más coincidente con el orden que considera todas las formas de dominancia que se pueden dar por los ordenamientos de los cinco índices. Como prueba adicional del resultado, se estimaron las distancias euclidianas entre las clasificaciones de los cinco índices, con respecto a la clasificación inducida por la matriz final A F , lo cual ratificó lo anterior; la distancia euclidiana más cercana al ordenamiento estabilizado fue para el IDHS (véase Figura 4).
Coincidencias de los órdenes de los índices con el orden estabilizado
Conclusiones y discusión
Además de tener en cuenta que los métodos objetivos, DE, C y E atienden a juicios diferentes en la asignación de pesos a los criterios de salud, educación y servicios, también se debe considerar que el IDH tiene una agregación geométrica mientras que la del resto de los índices es aritmética. Estas diferencias exhiben la riqueza en la diversidad de los índices comparados y, por ello, el ordenamiento que determine un índice, que según cierto razonamiento lógico lo señale como el idóneo para representar un ordenamiento que considera las dominancias que se dan entre las alternativas que se desean ordenar (estados de México), es relevante en la discusión de lo que se mide, como es el caso del desarrollo humano en este trabajo.
Así, el IDHS tuvo la mayor concordancia con el índice estabilizado, por lo tanto contiene más información que los otros, ya que al coincidir en un número mayor de veces con el ordenamiento estabilizado señala que fue el que captura mejor las dominancias expresadas en los índices comparados. Lo anterior da lugar a las observaciones siguientes.
La asignación de los pesos al IDH y al IDHS se hizo de forma subjetiva, y responden al principio de que los tres atributos (dimensiones) del desarrollo humano son igual de importantes para el desarrollo de las capacidades de las personas. Las diferencias entre ellos son: a) la dimensión para una vida digna (servicios en el IDHS e ingreso en el IDH) y b) la forma de agregación (aritmética en el IDHS y geométrica en el IDH). Estas diferencias, desfavorables para el IDH, apuntan a que los servicios (opciones objetivas de desarrollo) son una alternativa mejor, como recursos para una vida digna, que la ofrecida por el ingreso. Por supuesto, esto se ha debatido mucho entre los especialistas, pero el trabajo expuesto aquí muestra que así es, basado en un método de dominancia. Por otro lado, la agregación geométrica sesga el índice (en este caso el IDH) hacia el valor mínimo de los tres que lo constituyen, y obnubila las opciones de desarrollo en las otras dos dimensiones. En este sentido, hay una contradicción en el uso de ponderaciones iguales a las dimensiones, por considerar que tienen la misma importancia, y la agregación geométrica que favorece a la dimensión cuya medida sea la más baja de las tres. En síntesis, el IDHS muestra una condición más robusta que el IDH, según el criterio de dominancia.
En la comparación del IDHS con el IDHS/C, el IDHS/DE y el IDHS/E, lo más notable radica en la dominancia de éste, cuyos pesos se le asignaron de forma subjetiva, sobre tres índices construidos con información de la población para otorgarles pesos de manera objetiva. Por supuesto, en los tres índices la asignación de pesos se hace de acuerdo con ciertos criterios que, aunque objetivos, no dejan de tener la limitación de atenderlos sólo a ellos. Los índices construidos con los métodos C y DE se acercan, en cuanto a su dominancia, al IDHS; atienden al criterio de inequidad en la distribución de la salud, la educación y los servicios, lo que señala que las asignaciones subjetivas, hechas por el UNDP, tomaron en cuenta la inequidad de éstas, de modo heurístico o no, pero que aquí se constata con una medida de dominancia.
El IDH y el IDHS/E tienen menos coincidencias con el orden estabilizado; también son los más alejados según la distancia euclidiana inducida para ello. Resulta interesante la coincidencia entre el índice que actualmente usa el UNDP y el obtenido por el método de entropía. Este último obedece al criterio de equidad en la distribución de las dimensiones manejadas, es decir, en sentido contrario al de los métodos C y DE. Con ello, el IDH pondera más a la dimensión con distribución más equitativa entre los municipios y menos a la que está distribuida de forma más inequitativa. Desde la perspectiva del desarrollo humano, que se preocupa por las opciones que tienen las personas para desarrollar sus capacidades, el valor de los índices cuantifica estas opciones, y sus pesos la relevancia que se les da. Aquí, ponderar más las dimensiones distribuidas de forma más equitativa en la población es darle mayor valor a los aspectos en los que las condiciones de los habitantes son más iguales, y ponderar menos aquéllas en las que éstos son más desiguales. Lo anterior se presta a un análisis e indagación no contemplados en este trabajo, que se atisba para investigaciones futuras.
Conviene señalar que el hecho de que cuatro de los índices analizados incluyen los servicios y sólo uno la información del PIB, para representar la misma dimensión, no deja de ser una limitante metodológica. Además, los resultados encontrados mediante el criterio de dominancia no se extienden para otros indicadores, ni para los mismos correspondientes a años diferentes, sólo señalan cierta regularidad, mas no es posible asignar un criterio de certeza; por ello, al índice que resultó ser el más dominante se le denominó el más robusto y no el mejor, entendiendo por robustez que en su contraste con otros cuatro (tres de ellos con la misma dimensión para el ingreso) concilia mejor su ordenamiento con uno estabilizado, producto del de los cinco índices involucrados.
Por último, desde la perspectiva estadística, es necesario recordar que la media aritmética de un conjunto de valores, si proviene de una población cuya conducta no sea extrema (que los valores extremos no ocurran con probabilidades muy altas), entonces su estimación poseerá un número considerable de propiedades que otras estimaciones no tendrán. Por citar algunas, será insesgada, lineal, de mínima varianza, de máxima verosimilitud, la de momentos, la de mínimos cuadrados, equivariante y la de Bayes. En otras palabras, la media aritmética de un conjunto de valores, en condiciones que por lo general se cumplen en fenómenos aleatorios, resulta la estimación indicada para satisfacer varios criterios favorables de optimización y, quizá obedezca a ello que el IDHS sea la estimación más robusta para medir el desarrollo humano, de las cinco incluidas aquí.
Un trabajo que compare más índices (hay otros métodos para construirlos) podría confirmar los resultados expresados aquí, pero los considerados permiten apreciar las ideas que se tratan de exhibir, y dejan el trabajo en un tamaño razonable. Investigaciones futuras podrán llevar al manejo de un índice que incorpore los elementos sustantivos relevantes para los especialistas en desarrollo humano. Una posibilidad interesante es probar una metodología distinta y novedosa, propuesta por Veres (2014), en la cual la estimación del índice no se basa en los valores de los indicadores considerados, sino en la posición que cada uno tiene en relación con el conjunto de las demás.
Bibliografía
Aznar, Jerónimo y Francisco Guigarro. 2012. Nuevos métodos de valoración: modelos multicriterio. Valencia: Universitat Politécnica de Valencia. https://riunet.upv.es/bitstream/handle/10251/19181/nuevos%20M%C3%89todos%20de%20dvaloraci%C3%93N%20-20modelos%20multicriterio.pdf?sequence=1
Cherchye, Laurens, Erwin Ooghe y Tom Van Puyenbroeck. 2008. Robust human development rankings.The Journal of Economic InequalityVI (4): 287-321.
De la Torre, Rodolfo y Hector Moreno. 2010. Advances in sub national measurement of the human development index: the case of Mexico. UNDP. Human development research paper 2010/23.
Decancq, Koen y María Lugo. 2013. Weight in multidimensional indices of wellbeing: an overview. Econometrics Review XXII (1): 77-34.
DEMYC. 2015. Informe del desarrollo humano de México. www.chapingo.mx/dicifo/demyc/uac/bases/memo/memoria.html (9 de enero de 2015).
Diakoulaki, Danae, George Mavrotas y Lefteris Papayannakis. 1995. Determining objective weights in multiple criteria problems: the critic method. Computers and Operations Research XII (3): 763-770.
Foster, James E. y Amartya Sen. 1997. The welfare basis of real income comparisons: a survey. Journal of Economic LiteratureXVII (1): 1-45.
Frones, Ivar. 2007. Theorizing indicators: on indicators, signs and trends. Social Indicators Research LXXX (1): 5-23.
Gaye, Anie y Shereyasi Jha. 2010. A review of conceptual and measurement innovations in national and regional human development reports, 1998-2009. UNDP. Human development report, research paper 2010/21.
Hurdrliková, Lenka. 2013. Composite indicators as a useful tool for international comparison: the Europe 2020 example. Prague Economic Papers XXII (4): 459-473.
Kovacevic, Milorad. 2010. Review of HDI critiques and potential improvements. UNDP Human development research paper 2010/33.
Munda, Giuseppe y Michela Nardo. 2003. On the methodological foundations of composite indicators used for ranking countries. Joint Research Centre of the European Communities 1-19.
OECD. 2008. Handbook on constructing composite indicators: methodology and user guide. Joint Research Center of the European Commission.
PNUD. 1990. Desarrollo humano, informe 1990. Bogotá: Tercer Mundo Editores.
Podvezko, Valentinas. 2011. The comparative analysis of MCDA methods SAW and COPRAS. Inzinerine Ekonomica-Engineering Economics XXII (2): 134-146.
Ramírez, M. A. 1999. Índice de desarrollo humano del estado de Guanajuato. Revista del Centro de Desarrollo Humano de Guanajuato (3): 34.
Searle, Shayle R. 1982. Matrix algebra useful for statistics. Nueva York. John Wiley and Sons.
Sharpe, Andrew y Andrews Brendon. 2012. An assessment of weighting methodologies for composite indicators: the case of the index of economic well-being. Otawa: Centre of Study of Living Standars.
UNDP. 2010. Human develompment report 2010. Oxford: Oxford University Press.
UNDP. 1991. Human develompment report 1991. Oxford: Oxford University Press .
Veres Ferrer, Ernesto J. 2014. Medición del desarrollo humano: un índice alternativo al IDH-2010. Especial referencia a los países latinoamericanos. Investigación Económica LXXIII (288): 87-115.
Zardary, Hassan N., Kamal Ahmed, Sharif Moniruzzaman S. y Sulkifli Bin Y. 2015. Weighting methods and their effects on multi-criteria decision making model outcomes in water resources managament. Nueva York: Springer.
Zeleny, Milan y James Cochrane. 1982. Multiple criteria decision making. Nueva York: McGraw Hill.
